Continuing my tale about loading big raster datasets into PostGIS database with WKT Raster extension, I’d like to post an update about experience with processing overviews.
For testing purposes, I built excessive number of overviews for japan.tif dataset using gdaladdo utility:
$ gdaladdo -r average japan.tif 2 4 8 16 32 64 128
The command above produced 7 overviews with the following dimensions:
$ gdalinfo japan_2_4_8_16_32_128.tif | grep -m 1 Ov
Overviews: 7000x7000, 3500x3500, 1750x1750, 875x875, 438x438, 219x219, 110x110
Next, I loaded the whole dataset into PostGIS and WKT Raster enabled database using gdal2wktraster utility written in Python and available to download from the WKT Raster repository:
$ gdal2wktraster.py -r japan.tif -t japan_rb_128 \
-o japan_rb_128.sql \
--index --srid 4326 -k -m 128x128 -O -M -v
I’ve invented my favourite convention of naming database tables and here _japan_rb128 remembers what was source dataset (japan), that the output table is in regular blocking mode (rb) and size of block (tile) is 128x128 pixels (_128).
You can find meaning of all the switches by displaying usage message:
$ gdal2wktraster.py -h
After, literally, two hours of crunching Japan, the script ended with nice summary. It tells how many input raster datasets have been processed and how many database tables will be generated after _japan_rb128.sql is loaded into database as wall as how many blocks (tiles) will be loaded into output table as rows:
------------------------------------------------------------
Summary of GDAL to WKT Raster processing:
------------------------------------------------------------
Number of processed raster files: 1
List of generated tables (number of tiles):
1 japan_rb_128 (12100)
2 o_2_japan_rb_128 (3025)
3 o_4_japan_rb_128 (784)
4 o_8_japan_rb_128 (196)
5 o_16_japan_rb_128 (49)
6 o_32_japan_rb_128 (16)
7 o_64_japan_rb_128 (4)
8 o_128_japan_rb_128 (1)
The script generated output file _japan_rb128.sql of size of 1 593 387 714 bytes and it took 2 hours, so it’s not a bad idea to leave it overnight, as I did yesterday :-) Disk space occupied by this dataset will estimate around 750 MB.
The SQL file with japan.tif dump is ready to load into the database, but first extra table needs to be created for metadata of overviews, it is RASTER_OVERVIEWS table:
CREATE TABLE raster_overviews (
o_table_catalog character varying(256) NOT NULL,
o_table_schema character varying(256) NOT NULL,
o_table_name character varying(256) NOT NULL,
o_column character varying(256) NOT NULL,
r_table_catalog character varying(256) NOT NULL,
r_table_schema character varying(256) NOT NULL,
r_table_name character varying(256) NOT NULL,
r_column character varying(256) NOT NULL,
out_db boolean NOT NULL,
overview_factor integer NOT NULL,
CONSTRAINT raster_overviews_pk
PRIMARY KEY (o_table_catalog, o_table_schema, o_table_name, o_column))
The RASTER_OVERVIEWS solution was proposed by Martin Daly and officially approved as a part of WKT Raster Specification, however it’s been decided that:
No provision is provided, or suggested, for creating, updating, or deleting overviews.
That’s why the CREATE TABLE command needs to be issued manually.
Now, everything is ready to load the data.
psql -d japan -f japan_rb_128.sql
Tables with overviews are named according to another but simple convention: o
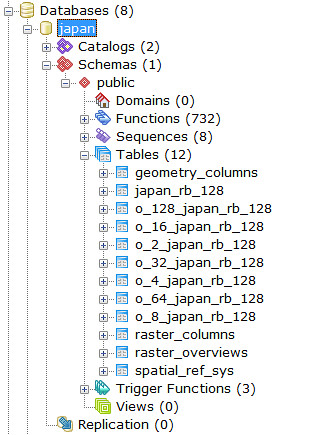
Now, the WKT Raster dataset consisting of base raster and 7 overviews is ready for testing.
List of software environment I used to perform the steps explained above:
OS: GNU Linux / Ubuntu 9.04 installed as a guest on VirtualBox 2.2.4
GEOS + PostGIS + WKT Raster: all built and installed from sources available from trunk branches in their SVN repositories.
